Detection of AI Generated Text and Analysis
 Motivation of the paper
Motivation of the paperThe Requirement:
Academia requires individuals to come up with some text of their own, based on their understanding. Using AI to generate text is considered an act of academic dishonesty, and is becoming a widespread problem. A method to check if some text was AI-generated would be of great use in today’s time, especially for professors and teachers. So, train an LLM to detect AI generated text.
Further Analytical Questions:
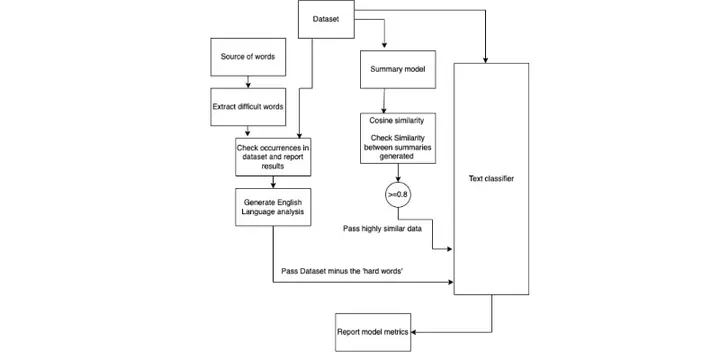
- Do humans use more difficult English words or does AI?
- If you use an LLM to summarize the texts genertated by humans and AI, how will our classifier perform?
How did we solve it?
- Trained a Bidirectional Encoder Representations from Transformers (BERT) text classification model on GPT-wiki-intro dataset. The specific BERT model is DistilBertForSequenceClassification
- Summarized input texts using Bidirectional Auto-Regressive Transformers (BART)
- Researched on the analytical questions
What did we achieve?
- Observed that human generated text has more complex English words than AI generated text
- Found that the BERT classifier focusses on semantics and structure than the difficulty of words used
- The classifier performs worse when there is a high similairty between summaries of human generated text and AI generated text
Technologies:
- Programming Languages: Python
- Data Manipulation: Pandas, NLTK
- ML Models: Hugging Face, PyTorch
Team:
- Abhimanyu Bellam, Vishnu Vinod Erapalli, Ankur Banerji, Harshwardhan Joshi